
- 01 二进制:不了解计算机的源头,你学什么编程.md
- 02 余数:原来取余操作本身就是个哈希函数.md
- 03 迭代法:不用编程语言的自带函数,你会如何计算平方根?.md
- 04 数学归纳法:如何用数学归纳提升代码的运行效率?.md
- 05 递归(上):泛化数学归纳,如何将复杂问题简单化?.md
- 06 递归(下):分而治之,从归并排序到MapReduce.md
- 07 排列:如何让计算机学会“田忌赛马”?.md
- 08 组合:如何让计算机安排世界杯的赛程?.md
- 09 动态规划(上):如何实现基于编辑距离的查询推荐?.md
- 10 动态规划(下):如何求得状态转移方程并进行编程实现?.md
- 11 树的深度优先搜索(上):如何才能高效率地查字典?.md
- 12 树的深度优先搜索(下):如何才能高效率地查字典?.md
- 13 树的广度优先搜索(上):人际关系的六度理论是真的吗?.md
- 14 树的广度优先搜索(下):为什么双向广度优先搜索的效率更高?.md
- 15 从树到图:如何让计算机学会看地图?.md
- 16 时间和空间复杂度(上):优化性能是否只是“纸上谈兵”?.md
- 17 时间和空间复杂度(下):如何使用六个法则进行复杂度分析?.md
- 18 总结课:数据结构、编程语句和基础算法体现了哪些数学思想?.md
- 19 概率和统计:编程为什么需要概率和统计?.md
- 20 概率基础(上):一篇文章帮你理解随机变量、概率分布和期望值.md
- 21 概率基础(下):联合概率、条件概率和贝叶斯法则,这些概率公式究竟能做什么?.md
- 22 朴素贝叶斯:如何让计算机学会自动分类?.md
- 23 文本分类:如何区分特定类型的新闻?.md
- 24 语言模型:如何使用链式法则和马尔科夫假设简化概率模型?.md
- 25 马尔科夫模型:从PageRank到语音识别,背后是什么模型在支撑?.md
- 26 信息熵:如何通过几个问题,测出你对应的武侠人物?.md
- 27 决策树:信息增益、增益比率和基尼指数的运用.md
- 28 熵、信息增益和卡方:如何寻找关键特征?.md
- 29 归一化和标准化:各种特征如何综合才是最合理的?.md
- 30 统计意义(上):如何通过显著性检验,判断你的A_B测试结果是不是巧合?.md
- 31 统计意义(下):如何通过显著性检验,判断你的A_B测试结果是不是巧合?.md
- 32 概率统计篇答疑和总结:为什么会有欠拟合和过拟合?.md
- 33 线性代数:线性代数到底都讲了些什么?.md
- 34 向量空间模型:如何让计算机理解现实事物之间的关系?.md
- 35 文本检索:如何让计算机处理自然语言?.md
- 36 文本聚类:如何过滤冗余的新闻?.md
- 37 矩阵(上):如何使用矩阵操作进行PageRank计算?.md
- 38 矩阵(下):如何使用矩阵操作进行协同过滤推荐?.md
- 39 线性回归(上):如何使用高斯消元求解线性方程组?.md
- 40 线性回归(中):如何使用最小二乘法进行直线拟合?.md
- 41 线性回归(下):如何使用最小二乘法进行效果验证?.md
- 42 PCA主成分分析(上):如何利用协方差矩阵来降维?.md
- 43 PCA主成分分析(下):为什么要计算协方差矩阵的特征值和特征向量?.md
- 44 奇异值分解:如何挖掘潜在的语义关系?.md
- 45 线性代数篇答疑和总结:矩阵乘法的几何意义是什么?.md
- 46 缓存系统:如何通过哈希表和队列实现高效访问?.md
- 47 搜索引擎(上):如何通过倒排索引和向量空间模型,打造一个简单的搜索引擎?.md
- 48 搜索引擎(下):如何通过查询的分类,让电商平台的搜索结果更相关?.md
- 49 推荐系统(上):如何实现基于相似度的协同过滤?.md
- 50 推荐系统(下):如何通过SVD分析用户和物品的矩阵?.md
- 51 综合应用篇答疑和总结:如何进行个性化用户画像的设计?.md
- 导读:程序员应该怎么学数学?.md
- 开篇词 作为程序员,为什么你应该学好数学?.md
- 数学专栏课外加餐(一) 我们为什么需要反码和补码?.md
- 数学专栏课外加餐(三):程序员需要读哪些数学书?.md
- 数学专栏课外加餐(二) 位操作的三个应用实例.md
- 结束语 从数学到编程,本身就是一个很长的链条.md
- 捐赠
49 推荐系统(上):如何实现基于相似度的协同过滤?
你好,我是黄申。
个性化推荐这种技术在各大互联网站点已经普遍使用了,系统会根据用户的使用习惯,主动提出一些建议,帮助他们发现一些可能感兴趣的电影、书籍或者是商品等等。在这方面,最经典的案例应该是美国的亚马逊电子商务网站,它是全球最大的B2C电商网站之一。在公司创立之初,最为出名的就是其丰富的图书品类,以及相应的推荐技术。亚马逊的推荐销售占比可以达到整体销售的30%左右。可见,对于公司来说,推荐系统也是销售的绝好机会。因此,接下来的两节,我会使用一个经典的数据集,带你进行推荐系统核心模块的设计和实现。
MovieLens数据集
在开始之前,我们先来认识一个知名的数据集,MovieLens。你可以在它的主页查看详细的信息。这个数据集最核心的内容是多位用户对不同电影的评分,此外,它也包括了一些电影和用户的属性信息,便于我们研究推荐结果是不是合理。因此,这个数据集经常用来做推荐系统、或者其他机器学习算法的测试集。
时至今日,这个数据集已经延伸出几个不同的版本,有不同的数据规模和更新日期。我这里使用的是一个最新的小规模数据集,包含了600位用户对于9000部电影的约10万条评分,最后更新于2018年9月。你可以在这里下载:http://files.grouplens.org/datasets/movielens/ml-latest-small.zip。
解压了这个zip压缩包之后,你会看到readme文件和四个csv文件(ratings、movies、links和tags)。其中最重要的是ratings,它包含了10万条评分,每条记录有4个字段,包括userId、movieId、rating、timestamp。userId表示每位用户的id,movieId是每部电影的ID,rating是这位用户对这部电影的评分,取值为0-5分。timestamp是时间戳。而movies包含了电影的主要属性信息,title和genres分别表示电影的标题和类型,一部电影可以属于多种类型。links和tags则包含了电影的其他属性信息。我们的实验主要使用ratings和movies里的数据。
设计的整体思路
有了用于实验的数据,接下来就要开始考虑如何设计这个推荐系统。我在第38期讲解了什么是协同过滤推荐算法、基于用户的协同过滤和基于物品的协同过滤。这一节我们就以协同过滤为基础,分别实现基于用户和物品的过滤。
根据协同过滤算法的核心思想,整个系统可以分为三个大的步骤。
第一步,用户评分的标准化。因为有些用户的打分比较宽松,而有些用户打分则比较挑剔。所以,我们需要使用标准化或者归一化,让不同用户的打分具有可比性,这里我会使用z分数标准化。
第二步,衡量和其他用户或者物品之间的相似度。我们这里的物品就是电影。在基于用户的过滤中,我们要找到相似的用户。在基于物品的过滤中,我们要找到相似的电影。我这里列出计算用户之间相似度\(us\)和物品之间相似度\(is\)的公式。之前我们讲过,这些都可以通过矩阵操作来实现。
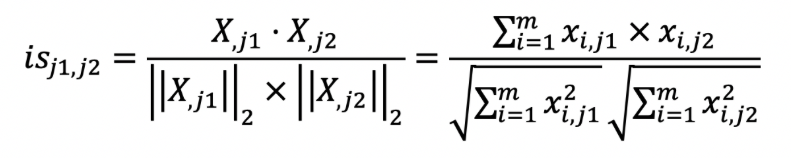
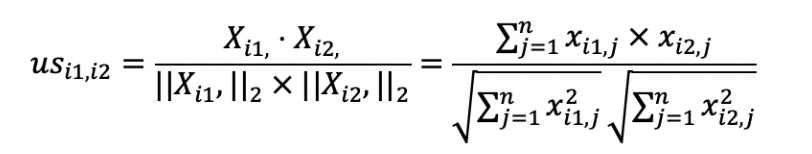
我们以基于用户的过滤为例。假设我们使用夹角余弦来衡量相似度,那么我们就可以采用用户评分的矩阵点乘自身的转置来计算余弦夹角。用户评分的矩阵\(X\)中,每一行是某位用户的行向量,每个分量表示这位用户对某部电影的打分。而矩阵\(X’\)的每一列是某个用户的列向量,每个分量表示用户对某部电影的打分。
我们假设\(XX’\)的结果为矩阵\(Y\),那么\(y\_{i,j}\)就表示用户\(i\)和用户\(j\)这两者喜好度向量的点乘结果,它就是夹角余弦公式中的分子。如果\(i\)等于\(j\),那么这个计算值也是夹角余弦公式分母的一部分。从矩阵的角度来看,\(Y\)中任何一个元素都可能用于夹角余弦公式的分子,而对角线上的值会用于夹角余弦公式的分母。因此,我们可以利用\(Y\)来计算任何两个用户之间的相似度。
之前我们使用了一个示例讲解过对于基于用户的协同过滤,如何计算矩阵\(Y\),以及如何使用\(Y\)来计算余弦夹角,我这里列出来给你参考。

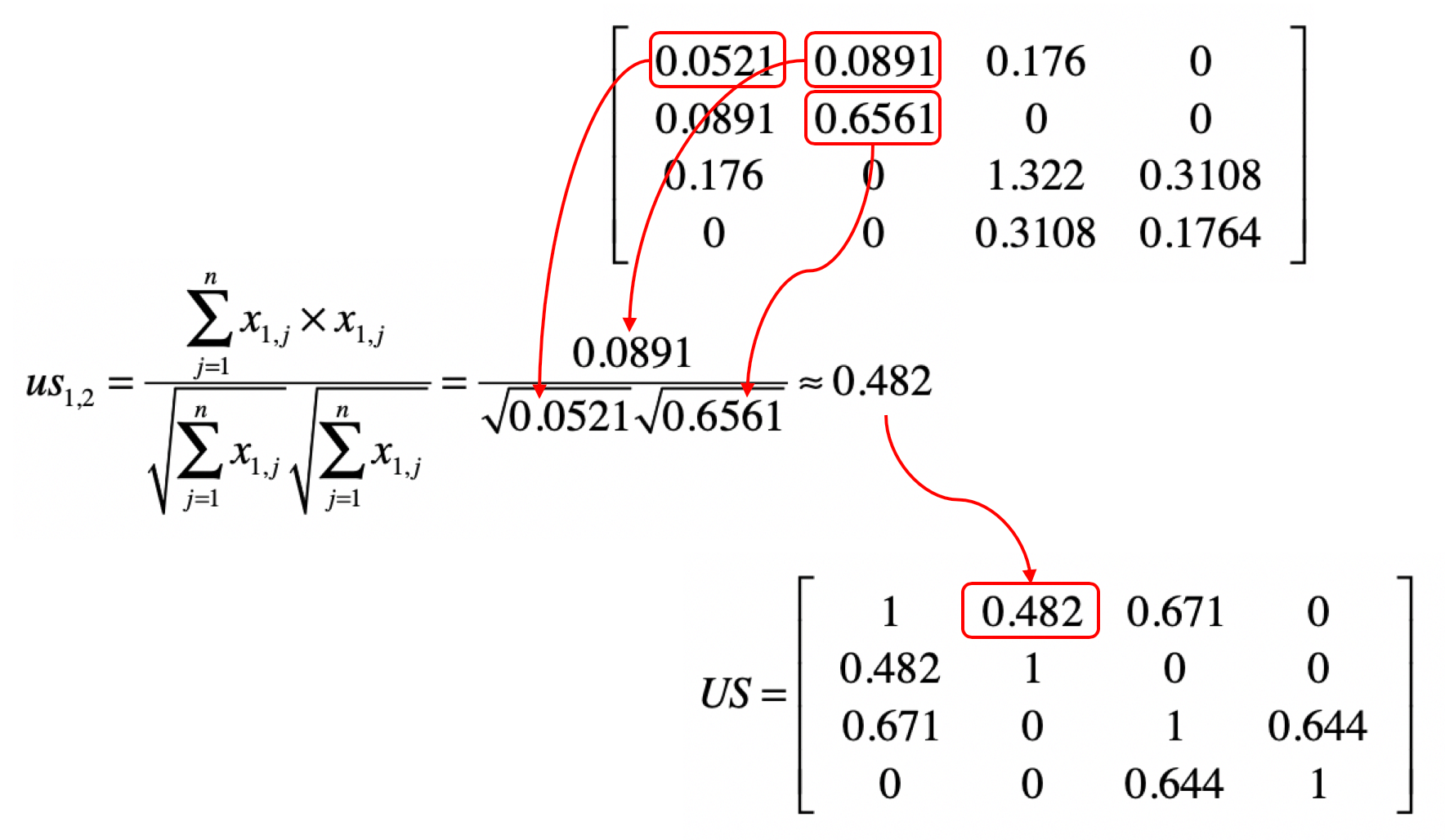
第三步,根据相似的用户或物品,给出预测的得分p。
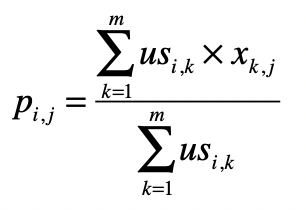
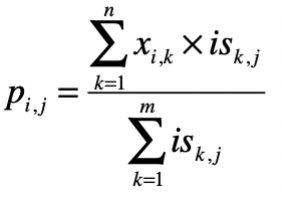
之前我们也解释过如何使用矩阵操作来实现这一步。还是以基于用户的过滤为例。假设通过第二步,我们已经得到用户相似度矩阵\(US\),\(US\)和评分矩阵\(X\)的点乘结果为矩阵\(USP\)。沿用前面的示例,结果就是下面这样。

然后对\(US\)按行求和,获得矩阵\(USR\)。

最终,我们使用\(USP\)和\(USR\)的元素对应除法,就可以求得任意用户对任意电影的评分矩阵\(P\)。
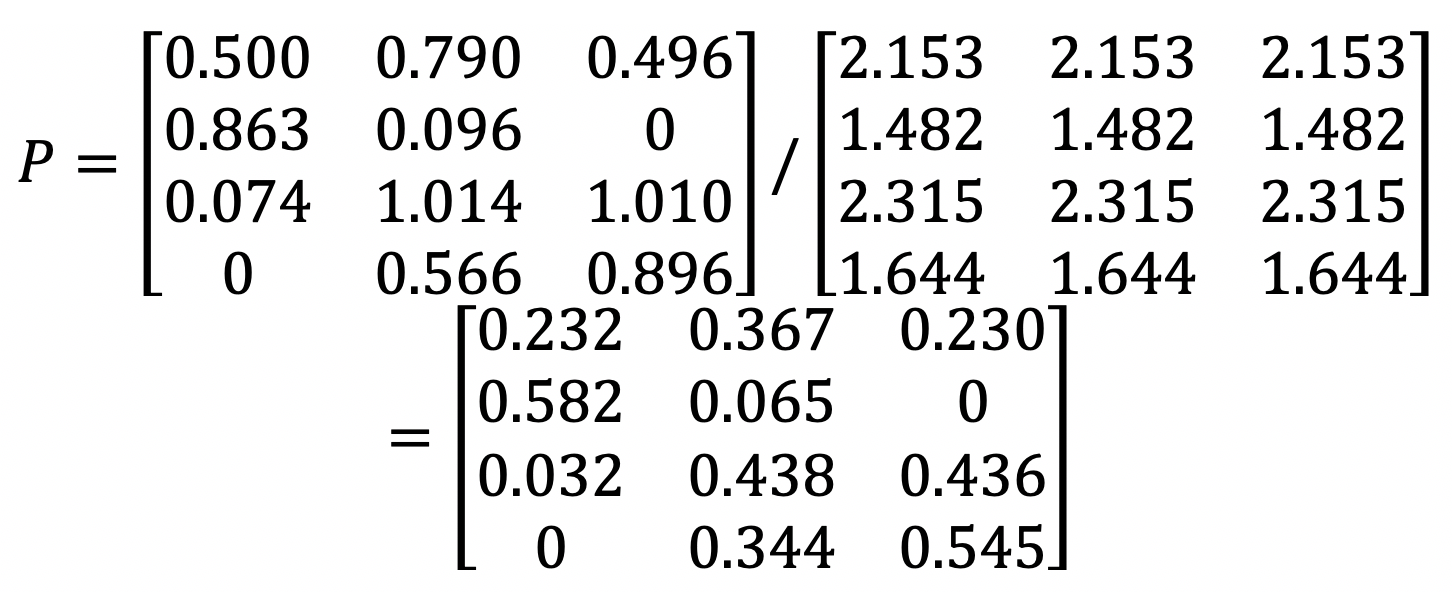
有了这个设计的思路,下面我们就可以使用Python进行实践了。
核心Python代码
在实现上述设计的三个主要步骤之前,我们还需要把解压后的csv文件加载到数组,并转为矩阵。下面我列出了主要的步骤和注释。需要注意的是,由于这个数据集中的用户和电影ID都是从1开始而不是从0开始,所以需要减去1,才能和Python数组中的索引一致。
import pandas as pd
from numpy import *
# 加载用户对电影的评分数据
df = pd.read_csv("/Users/shenhuang/Data/ml-latest-small/ratings.csv")
# 获取用户的数量和电影的数量
user_num = df["userId"].max()
movie_num = df["movieId"].max()
# 构造用户对电影的二元关系矩阵
user_rating = [[0.0] * movie_num for i in range(user_num)]
i = 0
for index, row in df.iterrows(): # 获取每行的index、row
# 由于用户和电影的ID都是从1开始,为了和Python的索引一致,减去1
userId = int(row["userId"]) - 1
movieId = int(row["movieId"]) - 1
# 设置用户对电影的评分
user_rating[userId][movieId] = row["rating"]
# 显示进度
i += 1
if i % 10000 == 0:
print(i)
# 把二维数组转化为矩阵
x = mat(user_rating)
print(x)
加载了数据之后,第一步就是对矩阵中的数据,以行为维度,进行标准化。
# 标准化每位用户的评分数据
from sklearn.preprocessing import scale
# 对每一行的数据,进行标准化
x_s = scale(x, with_mean=True, with_std=True, axis=1)
print("标准化后的矩阵:", x_s)
第二步是计算表示用户之间相似度的矩阵US。其中,y变量保存了矩阵X左乘转置矩阵X’的结果。而利用y变量中的元素,我们很容易就可以得到不同向量之间的夹角余弦。
# 获取XX'
y = x_s.dot(x_s.transpose())
print("XX'的结果是':", y)
# 获得用户相似度矩阵US
us = [[0.0] * user_num for i in range(user_num)]
for userId1 in range(user_num):
for userId2 in range(user_num):
# 通过矩阵Y中的元素,计算夹角余弦
us[userId1][userId2] = y[userId1][userId2] / sqrt((y[userId1][userId1] * y[userId2][userId2]))
在最后一步中,我们就可以进行基于用户的协同过滤推荐了。需要注意的是,我们还需要使用元素对应的除法来实现归一化。
# 通过用户之间的相似度,计算USP矩阵
usp = mat(us).dot(x_s)
# 求用于归一化的分母
usr = [0.0] * user_num
for userId in range(user_num):
usr[userId] = sum(us[userId])
# 进行元素对应的除法,完成归一化
p = divide(usp, mat(usr).transpose())
我们可以来看一个展示推荐效果的例子。在原始的评分数据中,我们看到ID为1的用户并没有对ID为2的电影进行评分。而在最终的矩阵P中,我们可以看出系统对用户1给电影2的评分做出了较高的预测,换句话说,系统认为用户1很可能会喜好电影2。进一步研究电影的标题和类型,我们会发现用户1对《玩具总动员》(1995年)这类冒险类和动作类的题材更感兴趣,所以推荐电影2《勇敢者的游戏》(1995年)也是合理的。
总结
在今天的内容中,我通过一个常用的实验数据,设计并实现了最简单的基于用户的协同过滤。我们最关心的是这个数据中,用户对电影的评分。有了这种二元关系,我们就能构建矩阵,并通过矩阵的操作来发现用户或物品之间的相似度,并进行基于用户或者物品的协同过滤。对于最终的计算结果,你可以尝试分析针对不同用户的推荐,看看协同过滤推荐的效果是不是合理。
在你分析推荐结果的时候,可能会参考movie.csv这个文件中所描述的电影类型。这些电影类型都是一开始人工标注好的。那么,有没有可能在没有这种标注数据的情况下,在一定程度上自动分析哪些电影属于同一个或者近似的类型呢?如果可以,有没有可能在这种自动划分电影类型的基础之上,给出电影的推荐呢?下一节,我会通过SVD奇异值分解,来进行这个方向的尝试。
思考题
今天我使用Python代码实现了基于用户的协同过滤。类似地,我们也可以采用矩阵操作来实现基于物品的协同过滤,请使用你擅长的语言来实现试试。
欢迎留言和我分享,也欢迎你在留言区写下今天的学习笔记。你可以点击“请朋友读”,把今天的内容分享给你的好友,和他一起精进。
© 2019 - 2023 Liangliang Lee. Powered by gin and hexo-theme-book.